cURL คืออะไร วิธีดึงรายละเอียดและทำระบบแชร์เว็บไซต์
cURL คืออะไร วิธีดึงรายละเอียดและทำระบบแชร์เว็บไซต์
cURL ย่อมาจากคำว่า Client for URLs เป็นคำสั่ง command line ที่ถูกเพิ่มเข้ามาในภาษา PHP ตั้งแต่เวอร์ชั่น 4.0.2 เป็นต้นมา จุดประสงค์หลักของคำสั่ง cURL ที่ถูกเพิ่มเข้ามาในภาษา PHP ก็เพื่อให้นักพัฒนาสามารถเขียนคำสั่งเพื่อติดต่อสื่อสารกับ Server ( Window, Linux ) และ Prototal ( http,https,ftp ) ที่มีความแตกต่างกัน
ขั้นตอนการทำงานหลักของคำสั่ง cURL
- 1. เริ่มต้นสร้าง curl resource ด้วยฟังก์ชัน curl_init()
- 2. กำหนด option ให้ curl resource ด้วยฟังก์ชัน curl_setopt() ตัวอย่างเช่น
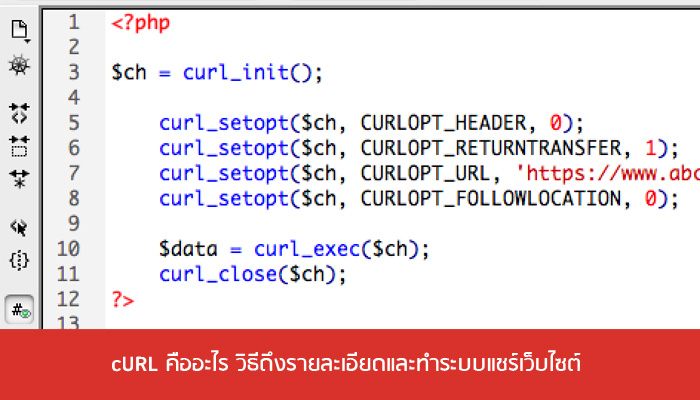
$ch = curl_init(); curl_setopt($ch, CURLOPT_HEADER, 0); // curl resource ตามด้วยชื่อ option และ value curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
- 3. สั่งเริ่มการทำงาน Execute curl resource ด้วยฟังก์ชัน curl_exec()
- 4. หลังจากได้ข้อมูลแล้วสั่งปิดการทำงานด้วยฟังก์ชัน curl_close()
โดยหลัก ๆ แล้วขั้นตอนการทำงานก็จะมีเท่านี้ จะเยอะหน่อยคือการกำหนด option ให้กับ curl resource ก่อนทำการ execute ซึ่งก็ขึ้นอยู่กับเงื่อนไขในการใช้งานของแต่ละงาน ข้อมูลจะถูกรีเทิร์นกลับมาหลังจากคำสั่ง execute
ตัวอย่างการใช้ cURL ในการดึงข้อมูลเว็บไซต์ทำระบบแชร์
เราสามารถใช้คำสั่ง cURL ในการดึงข้อมูลของเว็บไซต์เช่น title,description,image เราจะได้ข้อมูลคล้าย ๆ กับที่เวลาเราแชร์ลิงค์ใน facebook timeline โดยสามารถเขียนคำสั่งได้ดังนี้
function file_get_contents_curl($url) // ฟังก์ชั่นเริ่มต้น กำหนดค่า และสั่งทำงาน curl
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 0);
$data = curl_exec($ch);
curl_close($ch);
return $data;
}
$html = file_get_contents_curl("https://www.domain.com"); //โหลดข้อมูล html จากเว็บไซต์ทั่วไป
$doc = new DOMDocument();
@$doc->loadHTML($html); // ข้อมูลที่ได้จะเป็น html ใช้คำสั่ง loadHTML เพื่อแปลงให้อยู่ในรูปแบบ xml
จากโค๊ดด้านบนเราได้ใช้คำสั่ง cURL เพื่อดึงหน้าเว็บไซต์ทั้งหน้ามาแสดง ถ้าเราลอง echo $html จะเห็นว่าไฟล์นี้ได้ดึงหน้าเว็บไซต์มาเหมือน copy มาเลย แต่จุดประสงค์ของเราคือต้องการเอาข้อมูลบางส่วนบนหน้าเว็บไซต์เท่านั้น จึงจัดการกับข้อมูลที่เป็น html ให้อยู่ในรูปแบบไฟล์เอกสาร xml เพื่อจะเข้าถึงข้อมูล tag ต่าง ๆ ในหน้าเว็บไซต์ได้ง่ายขึ้น
หากไม่มีอะไรผิดพลาดและเราสามารถโหลดข้อมูลจากเว็บไซต์นั้น ๆ ได้ เราก็จะสามารถเข้าถึง tag ต่าง ๆ ในเว็บไซต์นั้นได้ผ่านคำสั่งของคลาส DOMDocument ได้ โดยสามารถเขียนคำสั่งได้ดังนี้
$nodes = $doc->getElementsByTagName('title');
$title = $nodes->item(0)->nodeValue;
$metas = $doc->getElementsByTagName('meta');
for ($i = 0; $i < $metas->length; $i++)
{
$meta = $metas->item($i);
if($meta->getAttribute('name') == 'description')
$description = $meta->getAttribute('content');
if($meta->getAttribute('name') == 'keywords')
$keywords = $meta->getAttribute('content');
}
echo "Title: $title". '<br/><br/>';
echo "Description: $description". '<br/><br/>';
echo "Keywords: $keywords";
หลังจากได้ข้อมูลทั้ง title, description, image, keyword เราก็สามารถนำไปทำระบบแชร์ได้ไม่ต่างจากการแชร์ลิงค์ในไทม์ไลน์ของเฟสบุ้คแล้วครับ
สามารถดูข้อมูล option ทั้งหมดของคำสั่ง cURL ได้ที่เว็บไซต์ http://php.net/manual/en/ref.curl.php