Tesseract คือ Engine ที่ใช้สำหรับกระบวนการแปลงสื่อสิ่งพิมพ์ เช่นกระดาษ นิตยาสาร สัญญา หรือข้อมูลอะไรก็ตามที่อยู่ในรูปของเอกสารกระดาษ ให้กลายเป็นเป็นข้อความ เรียกกระบวนการนี้ว่า Optical Character Recognition หรือเรียกสั้น ๆ ว่า OCR
Tesseract Engine สามารถแปลงข้อมูลในรูปภาพไปเป็นตัวอักษรภาษาต่าง ๆ ทั่วโลก เดิมที่ถูกพัฒนาโดย Hewlett-Packard ( HP ) และเปิดเป็นโอเพ่นซอร์สในปี 2005 จากนั้นในปี 2006 ทีมพัฒนาของ Google ได้นำมาพัฒนาต่อยอดให้มีความสามารถมากขึ้น สามารถเข้าดูได้ที่ https://opensource.google/projects/tesseract
ในบทความนี้จะมาแนะนำการติดตั้งและใช้งาน Tesseract OCR ในภาษา PHP บนระบบปฏิบัติการ Mac OS นะครับ สำหรับการทดสอบ เบื้องต้นให้เตรียม Environment ตามด้านล่างนะครับ
- ติดตั้ง homebrew package manager
- ติดตั้ง PHP 7.2 หรือเวอร์ชั่นที่สูงกว่า
ติดตั้ง Tesseract OCR
- เปิด terminal ขึ้นมาที่โฟลเด้อ ocr ติดตั้ง https://github.com/thiagoalessio/tesseract-ocr-for-php ผ่าน composer โดยใช้คำสั่งดังนี้ครับ
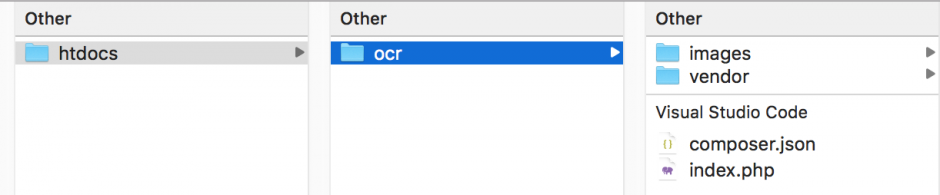
composer require thiagoalessio/tesseract_ocrเมื่อติดตั้งสำเร็จเราจะได้โครงสร้างโปรเจคตามรูปด้านล่าง ลบ compser.lock ทิ้งไป

- ติดตั้ง Tesseract OCR ใช้ homebrew โดยเปิด Terminal ขึ้นมาและพิมพ์คำสั่งดังนี้
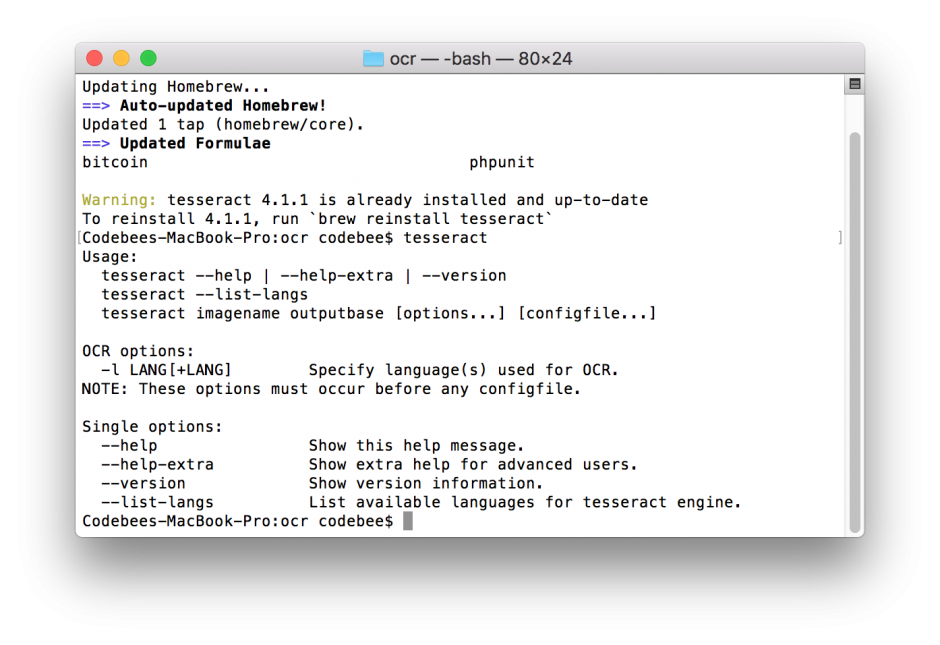
brew install tesseractหลังจากติดตั้ง tesseract เรียบร้อยแล้ว ถ้าเราอยากรู้คำสั่งต่างของ tesseract ให้พิมพ์ tesseract ที่ Terminal
tesseract –version คำสั่งสำหรับดูว่าเราติดตั้งเวอร์ชั่นอะไรไว้ในเครื่อง
tesseract –list-langs คำสั่งสำหรับตรวจสอบภาษาที่ tesseract สามารถ recognize ได้
- ทดสอบการทำงาน โดยให้สร้างไฟล์ index.php ไว้ในโฟลเด้อ ocr จากนั้น ลองหาภาพที่มีข้อความภาษาอังกฤษวางในโฟลเด้อ images ตั้งชื่อไฟล์ว่า eng.png ดูตัวอย่างตามภาพ
และรูปภาพที่มีข้อความภาษาอังกฤษอยู่ในภาพ ใช้สำหรับทดสอบ

คำสั่งใน index.php
require_once "vendor/autoload.php";
use thiagoalessio\TesseractOCR\TesseractOCR;
echo (new TesseractOCR('images/eng.png'))
->lang('eng')
->executable('/usr/local/Cellar/tesseract/4.1.1/bin/tesseract')
->run();
ในส่วนของ executable หากเราไม่ทราบว่า tesseract ถูกติดตั้งไว้ที่ path ไหน ให้ใช้คำสั่ง brew list tesseract เพื่อดู path ที่เราติดตั้ง tesseract ได้ ผลลัพธ์คำสั่งตามด้านล่าง
/usr/local/Cellar/tesseract/4.1.1/bin/tesseract
/usr/local/Cellar/tesseract/4.1.1/include/tesseract/ (19 files)
/usr/local/Cellar/tesseract/4.1.1/lib/libtesseract.4.dylib
/usr/local/Cellar/tesseract/4.1.1/lib/pkgconfig/tesseract.pc
/usr/local/Cellar/tesseract/4.1.1/lib/ (2 other files)
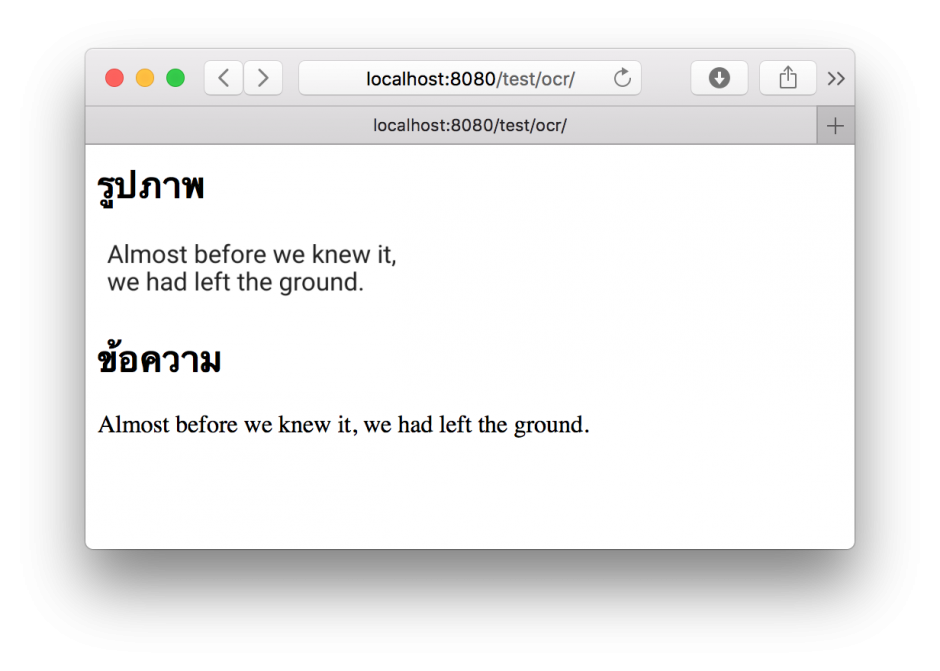
/usr/local/Cellar/tesseract/4.1.1/share/tessdata/ (35 files)ผลลัพธ์ที่ได้เมื่อเรารันคำสั่งใน index.php ผ่าน localhost:8080/ocr ตามรูปด้านล่างครับ สำหรับภาพที่ไม่ได้มีความซับซ้อนมาก เช่น ไม่มีพื้นหลัง ไม่มีเส้นตัดทับตัวอักษร ผลลัพธ์แม่นยำ 100% เลยครับ
ติดตั้ง tesseract ภาษาไทย
ติดตั้ง tesseract ภาษาไทย เบื้องต้นหลังจากเราติดตั้ง tesseract เรียบร้อยแล้ว จะมีภาษาที่สามารถ recognize ได้แค่ 3 ภาษานะครับ ในกรณีที่เราต้องการแปลงข้อมูลในภาพที่เป็นภาษาไทยให้เราติดตั้งภาษาใน tesseract เพิ่ม โดยใช้คำสั่ง
brew install tesseract-<langcode> สำหรับติดตั้งภาษาใดภาษาหนึ่ง
brew install tesseract-lang สำหรับติดตั้งทุกภาษาปรับ code ที่ไฟล์ index.php นิดหน่อยครับ โดยเพิ่มภาษาไทยเข้าไป
echo (new TesseractOCR('thai.png'))
->lang('tha','eng')
->executable('/usr/local/Cellar/tesseract/4.1.1/bin/tesseract')
->run(); ผลลัพธ์ที่ได้ สำหรับการแปลงเป็นภาษาไทย
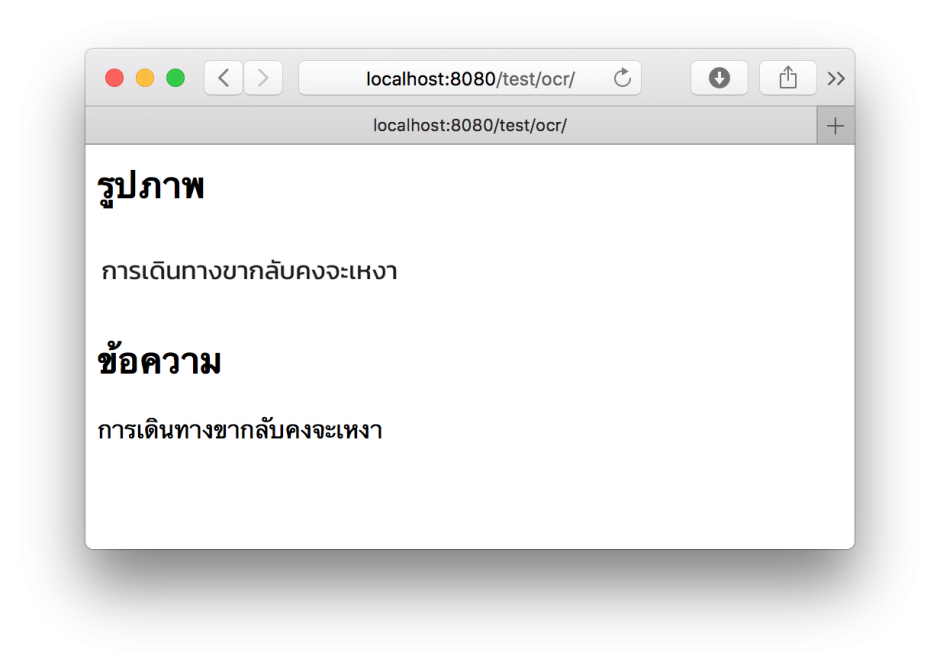
Tesseract OCR กับ รูปภาพที่ซับซ้อน
ลองทดสอบ Tesseract OCR กับระบบภาพ Captcha หลาย ๆ แบบ ตั้งแต่ง่าย ๆ จนถึงยากมาก ( แบบที่คนเองยังอ่านลำบาก )
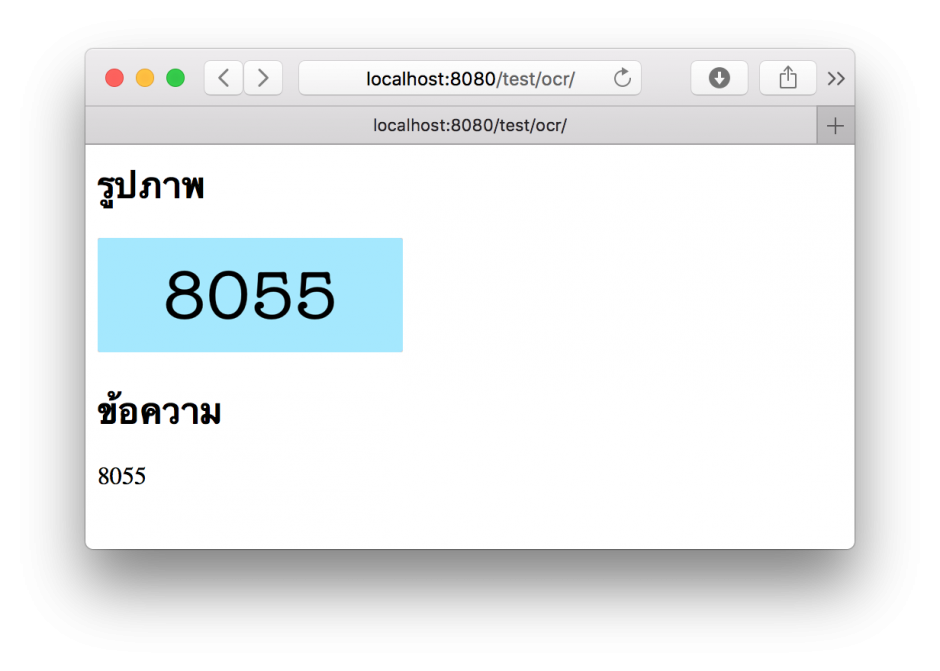
รูปแบบตัวเลขล้วน อ่านได้ปกติ
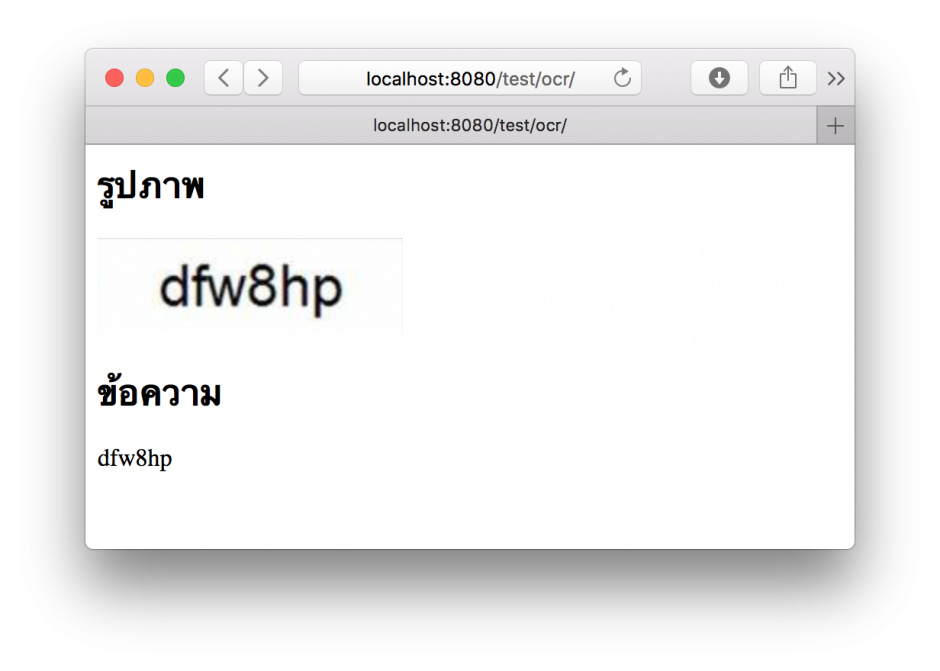
แบบข้อความผสมตัวเลข ยังอ่านได้อยู่
แบบเบลอ ๆ เอียง ๆ ยังพออ่านได้
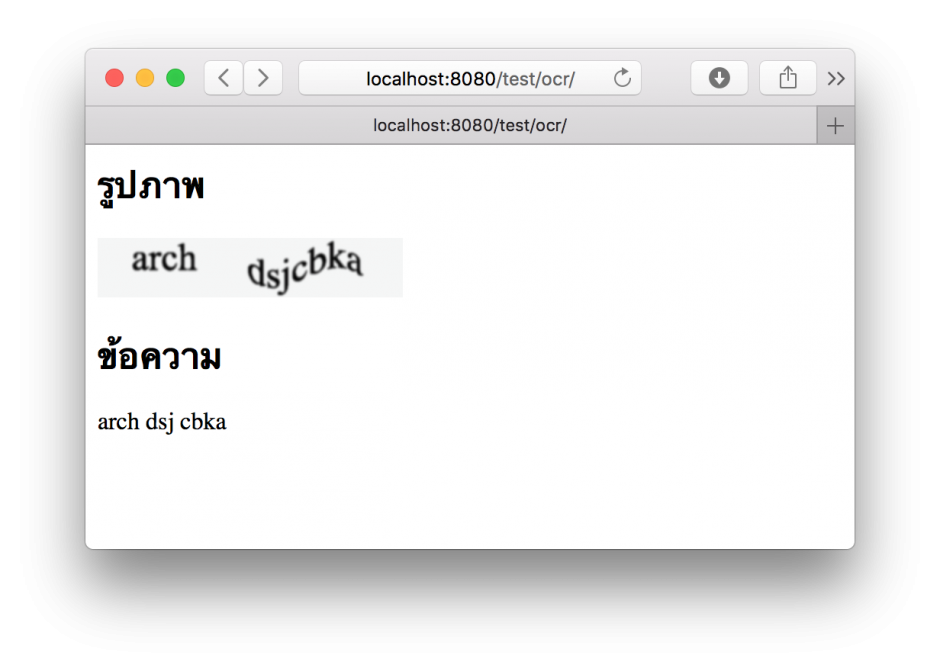
แบบยากมาก มีเส้นสีเดียวกันทับตัวอักษร อ่านไม่ได้แล้ว
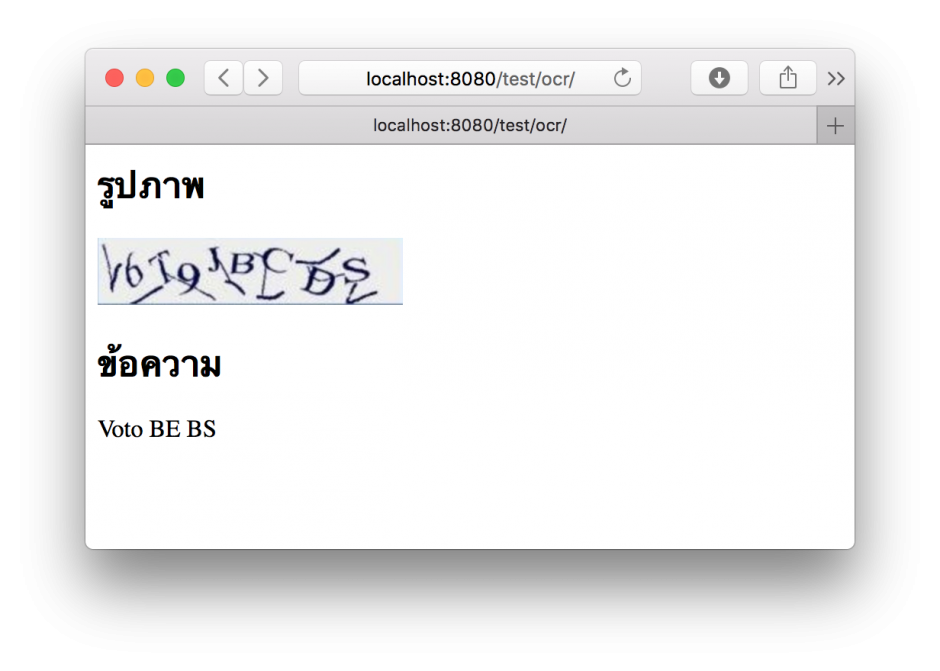
ขอบคุณข้อมูลจากหลาย ๆ ที่สำหรับการทดสอบ
- https://stackoverflow.com/questions/38091060/how-to-setup-and-running-tesseract-ocr-for-php-opensource
- https://github.com/thiagoalessio/tesseract-ocr-for-php
- https://github.com/tesseract-ocr/tesseract/wiki
- https://fonts.google.com